Benchmark and comparison of RPC solutions - part 1
rpclib 1.0.0 is finally here. For this release, I’ve also completed a benchmark suite which measures the performance of Google’s gRPC, Apache Thrift, Cap’n’Proto RPC and rpclib in certain situations. To highlight the pure overhead of calls via RPC, the performance of equivalent code through direct function calls is also included.
I also meant to include a comparison of APIs, but I realized halfway that analysing both the results and the APIs is going to be extremely lenghty, so I decided to split the post into two parts, the first part being the results, and the second part being comparison of the APIs. I’ll put the link here once that post is published.
Note that apart from rpclib, these RPC solutions are not strictly just “libraries”, rather they are complete packages with code generators and library implementations for various languages. For the sake of simplicity, I’m going to refer to them as libraries anyway.
How do we benchmark RPC libraries?
It’s hard to come up with a measurement that can be universally useful for comparing the performance of RPC libraries. As an example, we certainly don’t want to measure the network latency when performing calls, (since that’s outside the control of the implementations) but we definitely want to know about I/O performance.
After some consideration, I decided to create the following setup for all four libraries (plus direct calls):
- Each library creates a server and client in the same process
- Each client makes synchronous calls to its server
- Each connection is established via TCP on a local socket
- No SSL, authentication, etc.
The implementations are obviously different, but I did my best to use each library in the most equivalent fashion. It’s possible that I did not use each library in the most efficient way, since I don’t consider myself an expert of them (apart from rpclib, which I’m the author of). Please send a PR if you find me “cheating” any of the libs out of performance.
Details of benchmarking
Creating the clients and servers is only performed once before the iterations and not included in the measured times. In the benchmarks with generated data, the data generation is performed outside the benchmarks and a cache is used.
The data is processed in the benchmarks to the point of having a native C++ type available (that is, to mimic normal function calls). This is done with the assumption that most real-life code would have to do this processing (deserialization), and this sometimes involves copies.
Google Benchmark utilized for the measurements which performs the code under benchmark in large number of iterations, then measures an average CPU times and real (wall clock) times 1. Each benchmark is ran five times and the results are averaged. The plots are created using Python and Seaborn/Matplotlib.
In the following sections I’m going to present the three different benchmarks performed with each library, as well as the results. The system I used to run the benchmarks:
- Intel(R) Core(TM) i5-6200U CPU @ 2.30GHz (quad-core)
- 8GB system memory
The benchmark code can be found on github: rpclib benchmarks The code used for creating the plots can be found in this jupyter notebook.
1. Simple function call with one parameter and a return value
This benchmark measures the performance of a simple function call. If this really was a simple function call, it would look like this:
int get_answer(int num) {
return 41 + num;
}
(and this is the exact piece of code used in the benchmarks - direct calls the function directly, while the others do so through RPC).
Results
In terms of CPU times, rpclib seems to be the fastest of the RPC libraries in this particular case:
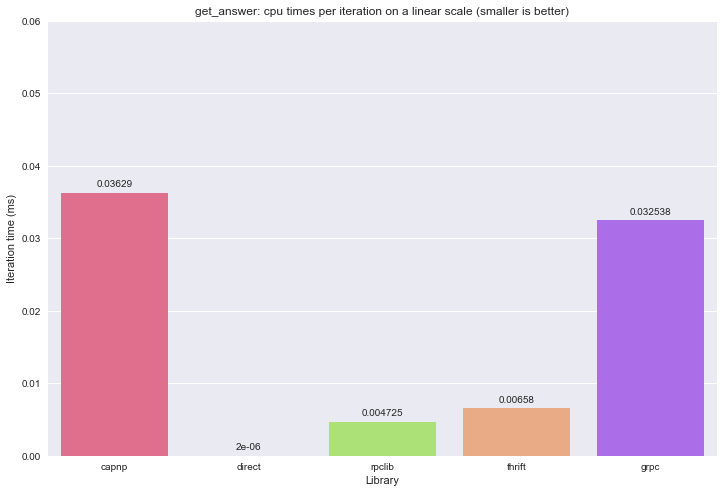
However, in wall clock times, rpclib takes almost twice as much time as Thrift does:
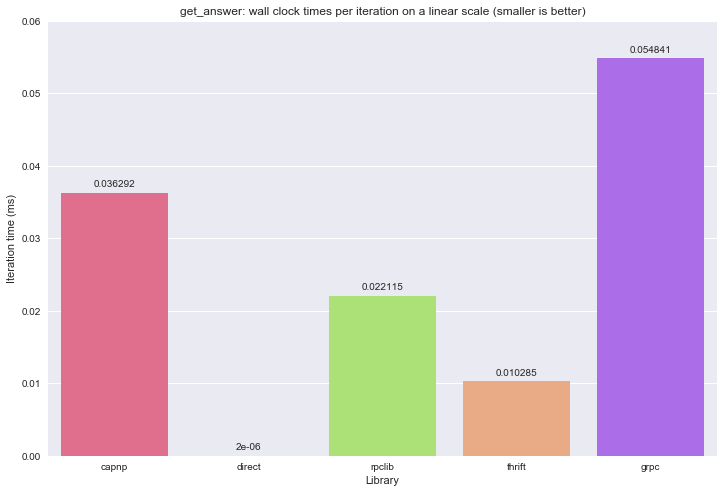
Cap’n’proto and gRPC are a lot slower than these two. I don’t know the reason for gRPC, but Kenton Varda, the authout of Cap’n’Proto pointed out the following:
In very trivial cases, Cap’n Proto is actually expected to perform worse than other libraries, because it is doing a bunch of extra bookkeeping to make the above cases work well, but that bookkeeping doesn’t end up providing any advantage. For example, when you’re only making one request at a time, using an async even loop adds tons of memory allocation and switching overhead that brings no advantage. But as soon as you have two simultaneous requests, this infrastructure becomes necessary. So, the result of your benchmark may be misleading: It will show a more trivial RPC systems to be “faster”, even though in real-world use cases their limitations would in fact make them much less efficient.
As we’ll see below in one of the more complicated benchmarks, he was right.
2. Large blob as return value
This is actually a set of benchmarks: a function returns binary buffers of increasing sizes. These buffers contain random-generated bytes and grow from 1KB to 16MB.
From this benchmark I had to exclude gRPC due to a rather serious memory management issue. Basically, once the benchmark hits the 4K blob size, gRPC eats all system memory in an instant. I’ve reported the issue when 1.1.0-pre was then the latest (pre-)release, but unfortunately 1.1.0 was released without a fix. There were subsequent releases without updates to the C++ implementations, so I did not test with those. It’s still possible that I made a mistake in my user code, but so far I couldn’t identify the root cause. Once the issue (or my code) is fixed, I’ll redo this part of the benchmark and add the gRPC results.
Results
First of all, the times measured here span a great scale, so I decided to create both linear and log scale plots.
In terms of CPU times, rpclib performs very well again, and for the larger blobs it’s almost as good as a direct copy. I attribute this to the efficiency of the msgpack-c++ implementation which is utilized by rpclib.
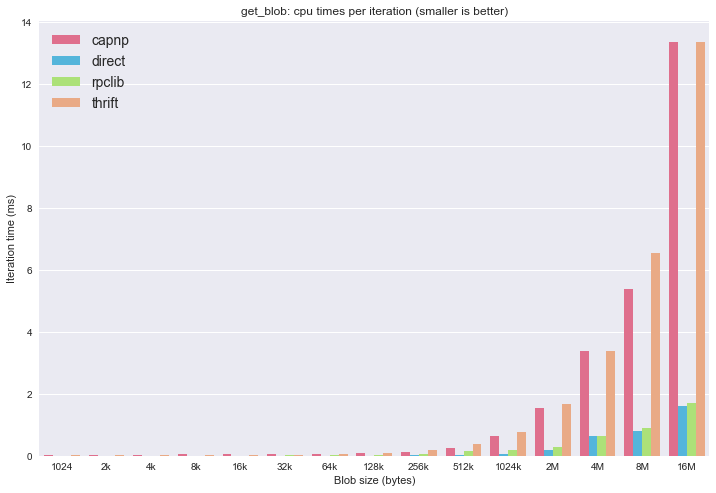
To see the smaller values, the same plot on a logarithmic scale:
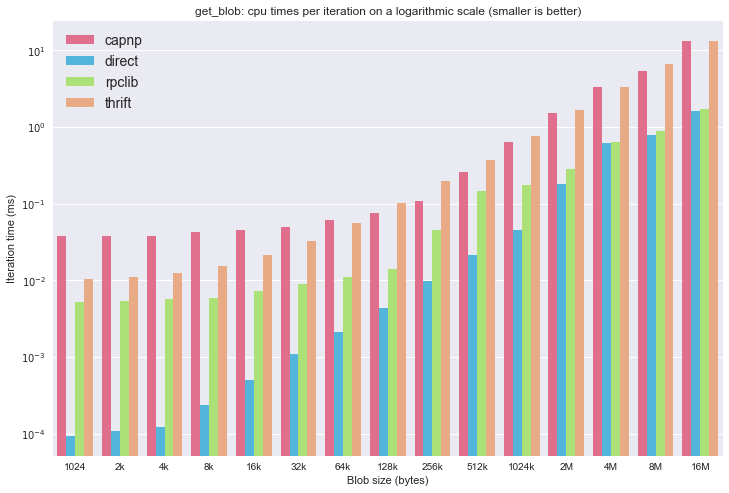
This reveals a weird jump in cpu times around the 256k mark for rpclib, for which I don’t know the reason yet. Apache Thrift seems to perform in the most consistent manner.
Let’s see the wall clock times. First, on a linear scale:
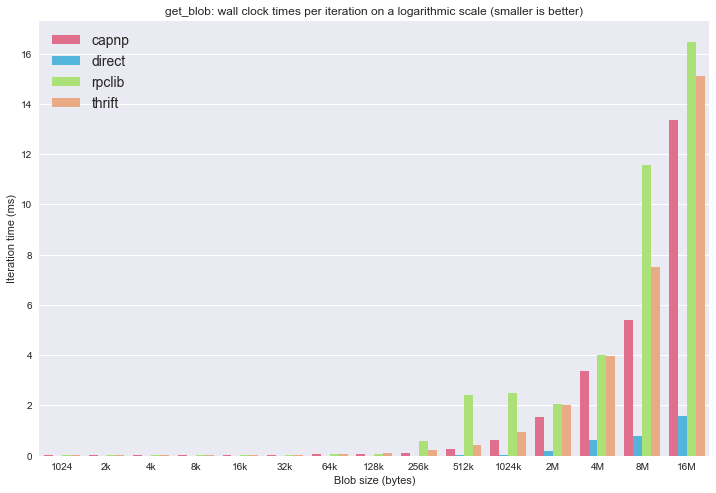
And on a logarithmic scale:
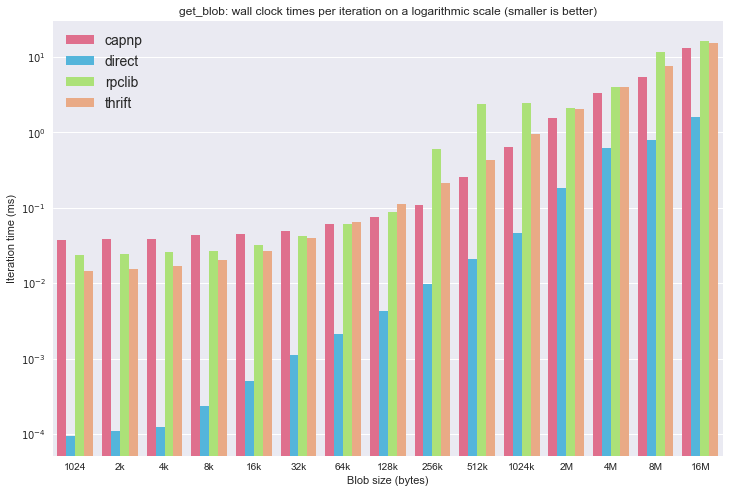
This again produces that unexpected jump in times for rpclib, making Apache Thrift the fastest again.
3. Deep nested structure with lots of data as return value
A complicated structure with a considerable depth and lots of data is interesting because it requires a good performing serializer and a compact data format. get_structs returns an array of such structures. The number 34 was choosen to be around 32, but to not be a power of two. The binary alignment of the structures is bad on purpose. For example:
struct Date {
int year;
char month;
char day;
};
This is where the vast majority of differing implementations had to be provided, since apart from rpclib, all libraries rely on IDLs and code generators.
Results
Let’s see the results.
CPU times:
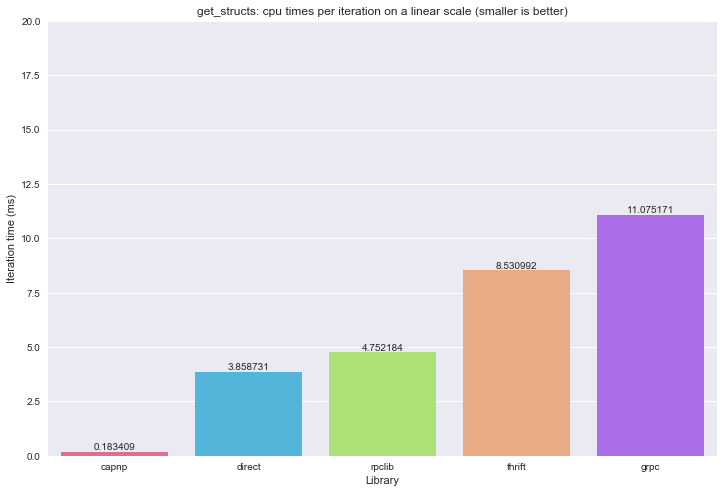
Wall clock times:
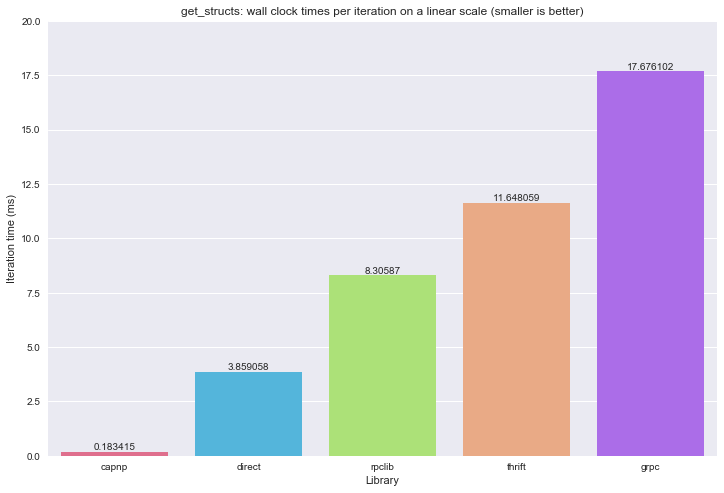
gRPC is the slowest again. I tried everything to avoid copies, but it seems that that it’s not possible to use cached data and avoid copying at the same time (let me know if I was wrong!)
And then… what? Cap’n’Proto is faster than a direct function call? Yes, it seems so. How it does that? I know that capnp does very well with this kind of workload, because it will very aggressively avoid copies and only set a bunch of pointers in the nested structures. Even then, I would except at least one copy to take place to during the RPC. I verified that on the client side all 34 structs are available. Maybe it detects that the server and client are in the same process and avoids even that copy. Let me know if there is a better explanation or if I made a mistake here.
Conclusion
If I was to rate each library, Apache Thrift would probably be the overall winner.
However, as cheap as this sounds, the “best” always depends on the type of work we do. Another important aspect of these benchmarks is that the results are very close to each other in most cases, with the largest differences being around 15ms (and that is during copying 16MB blobs).
When choosing an RPC solution, raw performance is usually not the only requirement: ease of use and cost of maintenance is important as well. In the second part, we’ll take a look at the same libraries from this point of view.
As the author of rpclib, I’m quite content with the results. There is definitely room for improvement and this small benchmark suite already helped identifying a good target (buffer management).
For the next logical step, it would be really nice to create a benchmark suite that runs in the cloud on actual separate machines and could measure performance under real and changing workloads.
-
Wall clock times are interesting in this case because those measurements are the ones that will include the I/O performance and efficiency of buffer management as well. ↩